モンテカルロ法(Pythonでの処理高速化)
■円周率の近似の続き。
前回、Python、javascriptの処理時間の比較を行い、Pythonでは演算部分(ランダムの数値の発生と円の内外の判定部分の演算)にかなり時間がかかった。
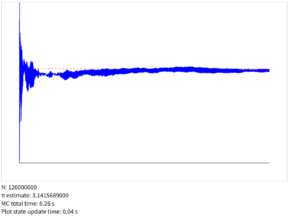
40000回(STEP)繰り返した後に1度グラフを更新。これを累計1.2億回まで行う(つまりグラフ更新は3000回)。下のコードで演算部分の時間を累算すると、5回平均で110秒ほどだが、Javascriptでは5,6秒ほど。
# ===== モンテカルロ演算時間計測 =====##################
t0 = time.perf_counter()
for _ in range(STEP):
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
total_count += 1
if x * x + y * y <= 1.0:
inside_count += 1
t1 = time.perf_counter()
#########################################################このコードを修正して処理を高速化ができないかみた。
ChatGPTの高速化の提案から、Numpyによるベクトル化、Numbaによる機械語への変換、Sobolの準乱数の使用を試した。いずれも40000回を行った結果でグラフ更新を行う。結果が下(単位は秒)。
| 試行 | Numpyベクトル化 | Numba機械語 | Sobol準乱数 |
| 1 | 2.82 | 4.37 | 1.35 |
| 2 | 2.61 | 2.12 | 1.31 |
| 3 | 2.59 | 2.12 | 1.33 |
| 4 | 5.26 | 2.13 | 1.33 |
| 5 | 3.56 | 2.11 | 1.34 |
| 平均 | 3.4 | 2.6 | 1.3 |
もとの110秒に比べて、どれもはるかに速くなっている。Javascriptが5,6秒であったことを考えてもこちらの方が速い(Javascriptももっと速い処理ができるだろうけど)。今は40000回に一度グラフを更新する縛りを入れているけど、もっとまとめて処理するようにすれば、さらに速くできるかもしれない。
行っているのはモンテカルロ法による円周率の近似なので、その使用に耐えれるものであれば厳密な乱数である必要はない。準乱数というものを使用した結果が一番速い処理となるが、求める少数点を小さいものにしていくと準乱数の使用が問題となるかもしれない。次回は縛りを外して、現実的な時間でどこまで細かい小数点のものが得られるか見てみたい。
それぞれのコードが下(基本的にChat GPTで生成)。
Numpy。40000回分(STEP)の乱数を1度で生成。
t0 = time.perf_counter()
x = np.random.uniform(-1, 1, STEP)
y = np.random.uniform(-1, 1, STEP)
inside_count += np.sum(x * x + y * y <= 1)
total_count += STEP
pi_est = 4 * inside_count / total_count
t1 = time.perf_counter()
Numba。@njitがついた箇所が機械語として処理されるよう。目に見えるコードから機械語への変換が必要ないのでその分速い。
@njit
def mc_step_numba(step):
inside = 0
for i in range(step):
# [0,1) → [-1,1)
x = 2.0 * np.random.random() - 1.0
y = 2.0 * np.random.random() - 1.0
if x*x + y*y <= 1.0:
inside += 1
return inside
(中略)
t0 = time.perf_counter()
inside_count += mc_step_numba(STEP)
total_count += STEP
pi_est = 4 * inside_count / total_count
t1 = time.perf_counter()
Sobol(scipy.statsからインポート)。準乱数とのこと。小数点が小さい場合、問題となるかみてみたい。
sampler = qmc.Sobol(d=2, scramble=False)
(中略)
t0 = time.perf_counter()
points = sampler.random(STEP) # [0,1)^2
x = points[:, 0]
y = points[:, 1]
inside = np.sum(x*x + y*y <= 1.0)
inside_count += inside
total_count += STEP
pi_est = 4.0 * inside_count / total_count
t1 = time.perf_counter()